

Подгонка параметров распределения
Глава 1 Глава 2
Как и в процедуре, описанной в главе 3, по поиску оптимального f при нормальном распределении, мы должны преобразовать необработанные торговые данные в стандартные единицы. Сначала мы вычтем среднее из каждой сделки, а затем разделим полученное значение на стандартное отклонение. Далее мы будем работать с данными в стандартных единицах. После того как мы приведем сделки к стандартным значениям, можно отсортировать их в порядке возрастания. На основе полученных данных мы сможем провести тест К-С. Нашей целью является поиск таких значений LOC, SCALE, SKEW и KURT, которые наилучшим образом подходят для фактического распределения сделок. Для определения «наилучшего приближения» мы полагаемся на тест К-С. Рассчитаем значения параметров, используя «метод грубой силы двадцатого века». Мы просчитаем каждую комбинацию для KURT от 3 до 0,5 с шагом -0,1 (мы можем также взять интервал от 0,5 до 3 с шагом 0,1, так как направление не имеет значения). Далее просчитаем каждую комбинацию для SCALE от 3 до 0,5 с шагом -0,1. Пока оставим LOC и SKEW равными 0. Таким образом, нам надо обработать следующие комбинации:
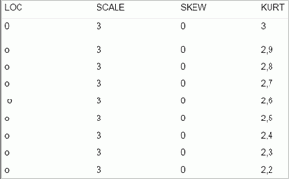
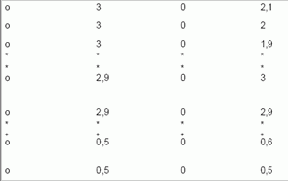
Для каждой комбинации проведем тест К-С. Комбинацию, которая даст наименьшую статистику К-С, будем считать оптимальной для параметров SKALE и KURT (на данный момент). Чтобы провести тест К-С для каждой комбинации, нам необходимо как фактическое распределение, так и теоретическое распределение (определяемое параметрами тестируемого характеристического распределения).
Мы уже знаем, как создать функцию распределения вероятности X/N, где N является общим числом сделок, а Х является рангом (от 1 до N) данной сделки.
Теперь нам надо рассчитать ФРВ для теоретического распределения при данных значениях параметров LOC, SCALE, SKEW и KURT. У нас есть характеристическая функция регулируемого распределения, она задается уравнением (4.06). Чтобы получить ФРВ из характеристической функции, необходимо найти интеграл характеристической функции. Мы обозначаем интеграл, т.е. площадь под кривой характеристической функции в точке X, как N(X).
Таким образом, так как уравнение (4.06) дает первую производную интеграла, мы обозначим уравнение (4.06) как N'(X). В большинстве случаев вы не сможете вывести интеграл функции, даже если вы опытный математик. Поэтому вместо интегрирования функции (4.06) мы будем использовать другой метод. Этот метод потребует больших усилий, но он применим к любой функции.
Вероятность для любой точки на графике характеристической функции можно оценить, если распределение представить себе как последовательность узких прямоугольников. Тогда для любого данного прямоугольника в распределении вы можете рассчитать вероятность, ассоциированную с этим прямоугольником, как отношение суммы площадей всех прямоугольников слева от вашего прямоугольника (включая площадь вашего прямоугольника) к сумме площадей всех прямоугольников в распределении. Чем больше прямоугольников вы используете, тем более точными будут полученные вероятности. Если бы вы использовали бесконечное число прямоугольников, то ваш расчет был бы точным.